

Vor allem Sprachlehrpersonen kennen das Problem: Gute Hörübungen sind schnell ausgeschöpft, während neue Themen und aktuelle Anlässe laufend neue Materialien erfordern. Gleichzeitig entstehen immer wieder neue Themen aus den Lebensrealitäten der Schüler*innen heraus, die sich für den Sprachunterricht eigenen und authentische Sprachmomente eröffnen würden. Passende Hörmaterialien auf dem richtigen Sprachniveau fehlen jedoch häufig.
Eigene Hörübungen aufzunehmen kostet Zeit, und passende Sprecher*innen für Dialoge stehen oft nicht zur Verfügung. Genau hier setzt SpeechSynthesis an: Die kostenlose und anmeldefreie Plattform ermöglicht es Lehrpersonen, innerhalb weniger Minuten eigene Hörtexte und Dialoge zu generieren und das unabhängig von vorhandenen (Unterrichts)materialien oder zusätzlichen Sprecher*innen.
Die Qualität von Text-to-Speech-Systemen (TTS) hängt nach wie vor stark vom verwendeten Modell ab. Während manche Stimmen sofort als Produkt der Künstlichen Intelligenz erkennbar sind, erzeugen andere natürliche Ergebnisse. SpeechSynthesis stellt hierfür mehr als 600 Stimmen in unterschiedlichen Sprachen und Dialekten zur Verfügung. Einerseits können damit neue Hörübungen im einfachen Modus mit wenigen Klicks erstellt werden. Andererseits bietet die Plattform einen leistungsstarken SSML-Editor, mit dem Lehrpersonen Prosodie, Stil, Pausen oder sogar mehrere Sprecher*innen individuell festlegen können.
Was ist SpeechSynthesis? Das Wichtigste im Überblick
SpeechSynthesis ist eine cloudbasierte Web-App und somit auf allen gängigen Geräten und Browsern nutzbar. Die Plattform ist seit 2024 verfügbar und bietet momentan über 600 KI-Stimmen in unterschiedlichen Sprachen und Dialekten, die ohne Registrierung oder Einrichtung genutzt werden können, um Text mit bis zu 20.000 Zeichen in gesprochene Sprache umzuwandeln.
Viele der verfügbaren Stimmen wirken überraschend natürlich (vor allem, wenn ihr Name “HD” enthält) und eignen sich gut für den Unterricht. Andere weisen hingegen starke Qualitätsunterschiede auf und sind eindeutig als KI-Stimme erkennbar. Geschwindigkeit, Tonhöhe und Lautstärke lassen sich bereits im einfachen Modus auf die Zielgruppe anpassen.
Beim Datenschutz verspricht die Plattform weder die eingegebenen Texte noch die generierten Audiodateien dauerhaft zu speichern. Die im Prozess entstandenen Audiodateien lassen sich in verschiedenen Dateiformaten (z.B. MP3) herunterladen und anschließend privat sowie kommerziell nutzen.
Die einfache Variante: Text-to-Speech durch simple Eingaben
Der einfachste Weg, um mit SpeechSynthesis Text-to-Speech-Ergebnisse zu erstellen, findet sich über den Reiter “TEXT” auf der Startseite. Diese Variante eignet sich besonders für Monologe oder kürzere Hörtexte, indem ein vorbereiteter Text – egal ob Satz, Absatz oder längerer Artikel – in das Textfeld übertragen wird:

Um das Ergebnis individuell anzupassen, bietet die Plattform unter “Erweiterte Einstellungen” verschiedene Möglichkeiten, um Sprache, Stimme, Sprechgeschwindigkeit (Rate), Tonhöhe oder Lautstärke festzulegen:
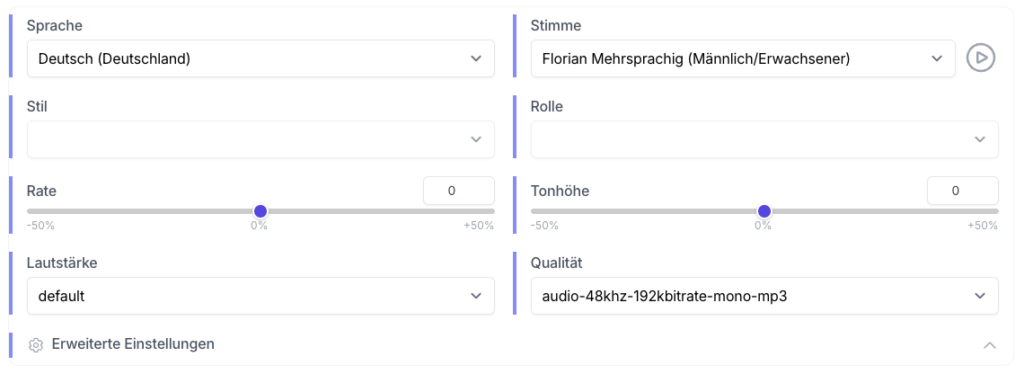
Besonders die große Auswahl an Stimmen kann anfangs etwas überwältigend wirken. Für jede Stimme steht daher zur Unterstützung eine Hörprobe zur Verfügung:

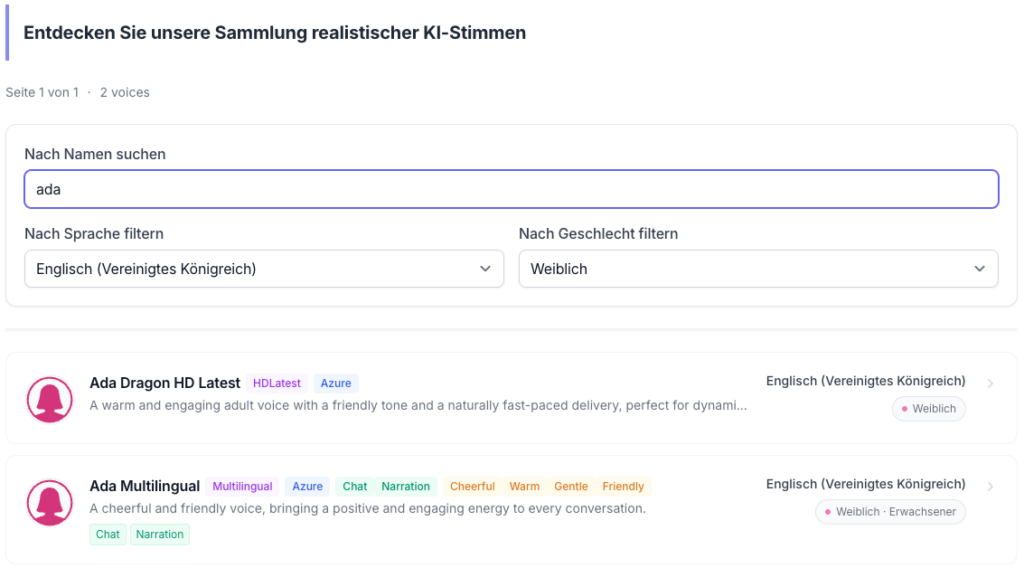
Der Navigationspunkt Stimmen am oberen Bildschirmrand bietet Nutzer*innen zusätzlich eine nach Sprache und Geschlecht filterbare Übersicht. Hier geben auch farbcodierte Tags Hinweise auf verfügbare Sprechstile (gelb) und empfohlene Einsatzbereiche (grün):
Sind die gewünschten Voreinstellungen abgeschlossen, startet der Button “Synthesieren” die Audioerstellung. Ist dieser Prozess abgeschlossen, werden auch die Buttons zum Abspielen und Herunterladen der Datei verfügbar:

Das Ergebnis hört sich in diesem Fall auf Deutsch so an:
Oder in anderen Sprachen so:
Englisch
Französisch
Spanisch
Italienisch
Wer es präziser braucht: Kontrolle über SSML
Während die simple Text-to-Speech-Funktion der Plattform für Monologe und einfache Hörübungen geeignet ist, bietet SpeechSynthesis mit dem SSML-Editor auch weitere Gestaltungsmöglichkeiten. SSML (Speech Synthesis Markup Language) ist dabei eine standardisierte Auszeichnungssprache, mit der sich verschiedene Aspekte der Sprachsynthese gezielt steuern lassen. Dazu zählen beispielsweise Stimme, Lautstärke, Tonhöhe, Sprechgeschwindigkeit, Betonungen oder Pausen.
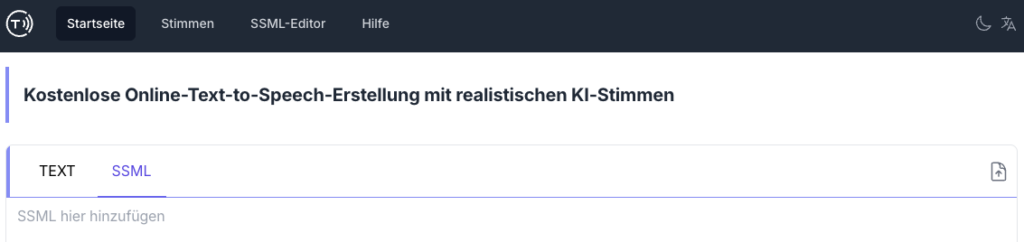
Damit Lehrpersonen diese Möglichkeit nutzen können, ohne selbst SSML-Code schreiben zu müssen, stellt SpeechSynthesis einen intuitiven SSML-Editor zur Verfügung:
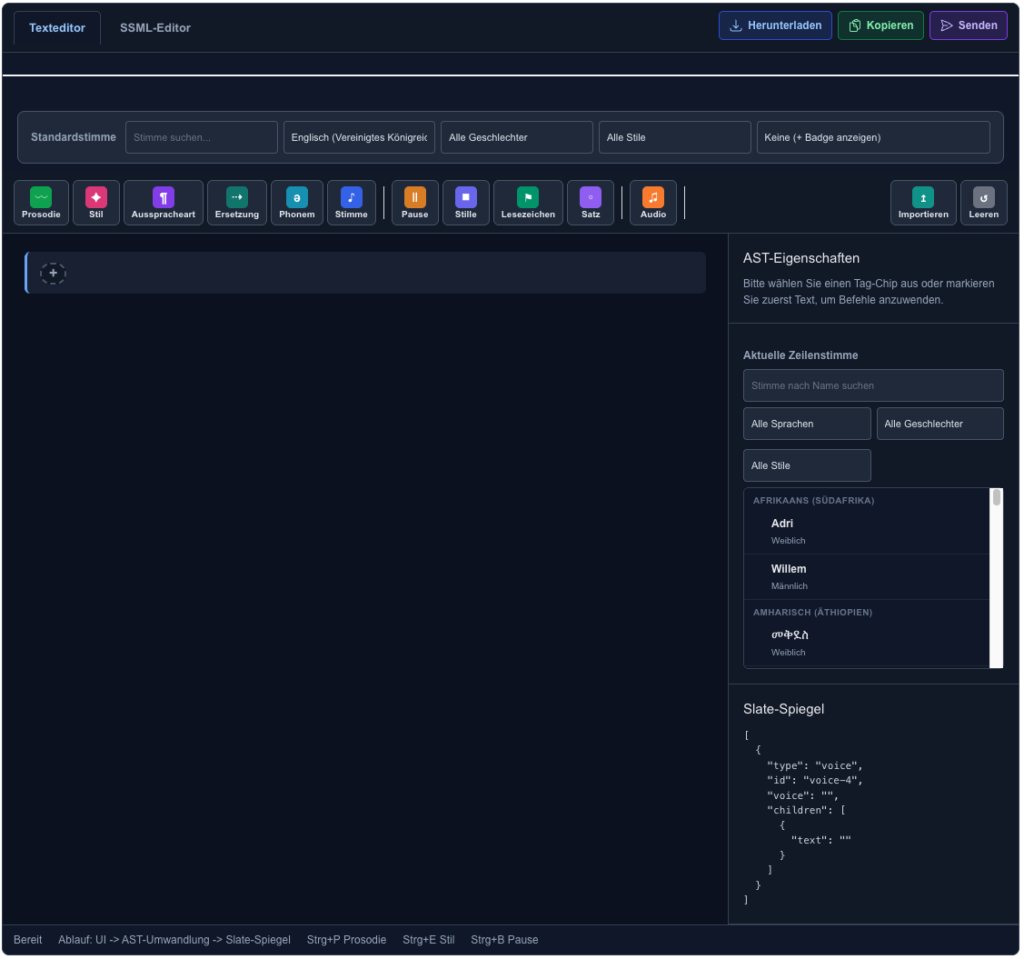
Der SSML-Editor bietet ein Eingabefeld für den zu sprechenden Text. Dieser kann entweder direkt eingetippt oder über den Button “Importieren” aus einer .txt-Datei übernommen werden:
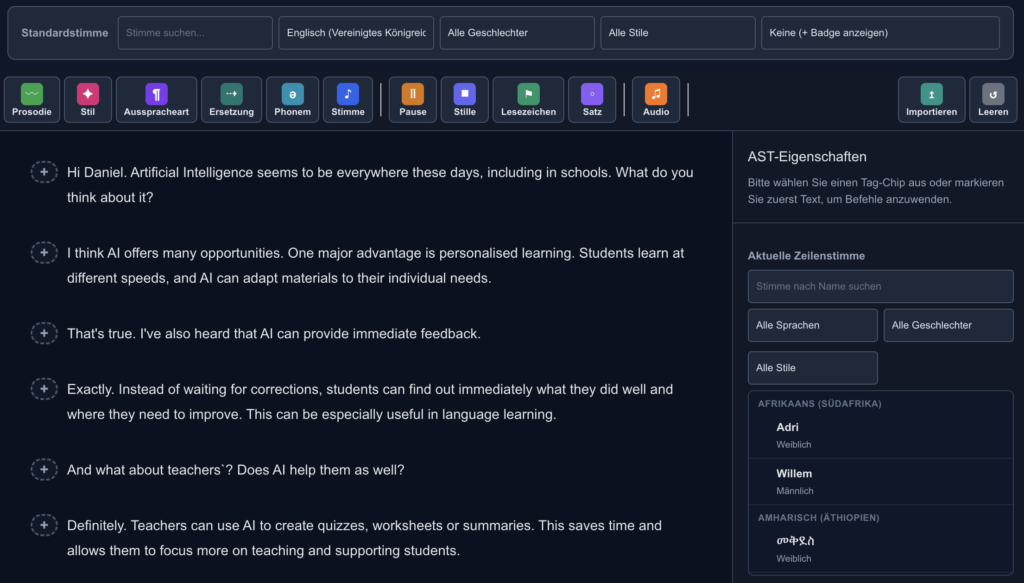
Erstellen eines Dialogs über Absätze
Um einen Dialog zu erstellen, wird für jeden Wechsel zwischen den Sprecher*innen ein Absatz angelegt:
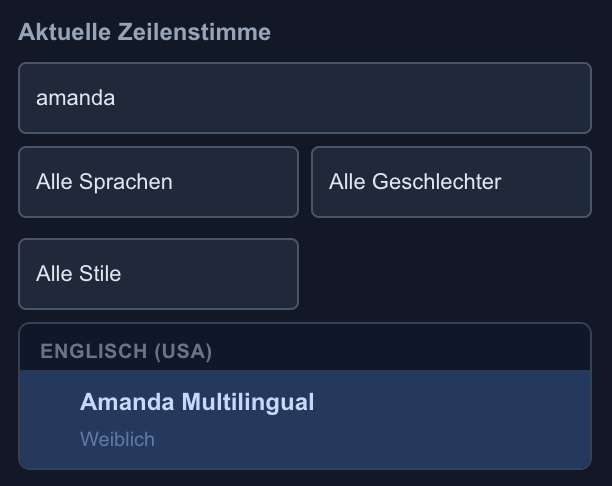
Um einem bestimmten Absatz nun eine spezifische Stimme zuzuweisen, wird dieser zuerst durch einen Klick ausgewählt:

Auf der rechten Seite des Editors kann im Abschnitt “Aktuelle Zeilenstimme” über die Suche direkt nach einer bestimmten Stimme gesucht, oder über die Filter für Sprache, Geschlecht und Stil sortiert werden. Für den Beispieldialog wurden die Stimmen “Amanda Multilingual” und “Arjun Dragon HD Latest“ verwendet:
Ein Klick auf die gewünschte Stimme ordnet diese dem derzeit ausgewählten Absatz zu. Dieser Schritt muss für alle Absätze durchgeführt werden, da SpeechSynthesis nur vollständig zugewiesene Sprecher*innenrollen verarbeiten kann.

Anpassen von Prosodie, Stil und Pausen
Neben der Auswahl unterschiedlicher Stimmen lassen sich auch Prosodie, Stil, Betonungen und Pausen anpassen. Dazu wird der gewünschte Textabschnitt markiert und anschließend die entsprechende Funktion in der Werkzeugleiste ausgewählt.
Im Beispiel wird in den Absätzen von Arjun die Geschwindigkeit um 10 % erhöht. Nach dem Markieren des Textes wird die Funktion “Prosodie” ausgewählt. Durch einen Klick auf den gesetzten Tag können die Feineinstellungen über die Schieberegler auf der rechten Seite vorgenommen werden:

Diese Arbeitsschritte bleiben immer gleich:
Text markieren > Funktion auswählen > gesetzten Tag anklicken > Einstellungen auf der rechten Seite anpassen
Hierzu ist anfangs ein wenig Ausprobieren und Einarbeitungszeit notwendig – mit der Zeit passieren diese Schritte aber automatisch und intuitiv.
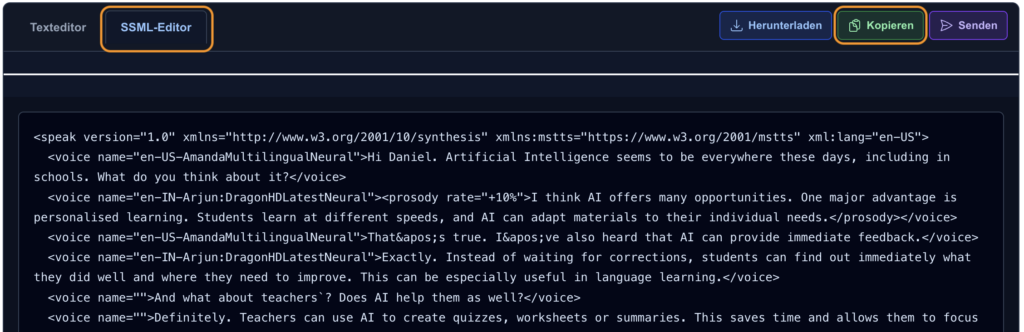
Übertragen der SSML-Anweisungen
Nachdem Sie alle Anpassungen vorgenommen haben, wechseln Sie zum Reiter „SSML-Editor“. Dort können Sie die erzeugten SSML-Anweisungen einsehen und über den Button „Kopieren“ direkt in die Zwischenablage übernehmen:
Öffnen Sie nun in einem neuen Fenster oder Tab die Startseite von SpeechSynthesis.
Behalten Sie den SSML-Editor dabei aber unbedingt offen, um nachträglich noch Änderungen durchführen zu können! Wird dieses Fenster geschlossen, wird alles gelöscht, was Sie bereits erstellt haben. Es empfiehlt sich, die fertigen SSML-Anweisungen in einem separaten Dokument zwischenzuspeichern, da diese im SSML-Editor wieder eingefügt und weiterbearbeitet werden können!
Wechseln Sie anschließend auf den Reiter “SSML” und fügen Sie die kopierten Anweisungen ein:

Der Button “Synthesieren” startet wie gewohnt die Audioerstellung. Gelegentlich kann es passieren, dass eine Fehlermeldung erscheint und die Verarbeitung nicht sofort beginnt.
In diesen Fällen genügt es meist, den Button “Synthesieren” erneut (auch mehrmals) anzuklicken, um die Verarbeitung erfolgreich zu starten.
TTS in der Praxis: Ein Listening Task zum Thema AI in Education
Probieren Sie die entstandene Listening-Übung für den Englischunterricht aus und lösen Sie eines der beiden Aufgabenformate dazu (Multiple Choice oder Sentence Completion):
Fazit
SpeechSynthesis liefert Lehrpersonen ein kostenloses und einfach zu bedienendes Werkzeug, um innerhalb weniger Minuten eigene Hörübungen zu erstellen. Nach ein wenig Einarbeitungszeit bietet die Plattform vor allem für den Sprachunterricht die Möglichkeit, aktuelle Themen, Interessen der Schüler*innen oder differenzierte Aufgabenstellungen schnell in authentisch wirkende Audioformate zu übertragen. Nicht alle Stimmen überzeugen, doch bei über 600 Variationen lassen sich einige finden, die konkret im Unterricht eingesetzt werden können.
SpeechSynthesis
+ im einfachen Modus sind keine Vorkenntnisse erforderlich
+ SSML-Editor bietet zahlreiche Optionen zur Individualisierung der Ergebnisse für den Unterricht
+ neue Hörübungen können an die Bedürfnisse und Interessen der Schüler*innen angepasst werden
+ regionale Stimmen fördern das Sprachverständnis der Schüler*innen
+ kostenlos, plattformunabhängig und ohne Account nutzbar
+ keine Weitergabe der eingegebenen Texte oder der erstellten Audiodateien
– nicht alle der 600+ Stimmen überzeugen
– im SSML-Modus ist Einarbeitung notwendig
– gelegentliche Fehlermeldungen beim Synthesieren verzögern die Erstellung
Dieser Text wurde mit Hilfe von KI (ChatGPT 5.5) überarbeitet. Die Verantwortung über Inhalt, Idee und Ausführung liegen alleine beim Autor. Beitragsbild generiert mit ChatGPT 5.5; OpenAI, 2026.